【MySQL】データベースのパーティショニングとはなんぞやという話
パーティショニングについての覚書。 一応 MySQL が前提。先に具体的な実体を書いたあと、それがパフォーマンス向上にどう寄与するのかを書きます。
パーティショニング is 何
簡単に言えば、データベースのテーブルを物理的に分割することです。テーブルのデータが分割されてしまっても、外からは論理的(透過的)に単一のテーブルとして見えます。なので、以下の図のようにクライアントや DML レイヤはそれを意識する必要はありません。p1 や p2 は分割されたパーティションを表しています。

この透過性は MySQL サーバによって提供されています。また、ストレージエンジンは分割された各パーティションを独立したテーブルのように扱います。これを図にすると次のような感じになります。
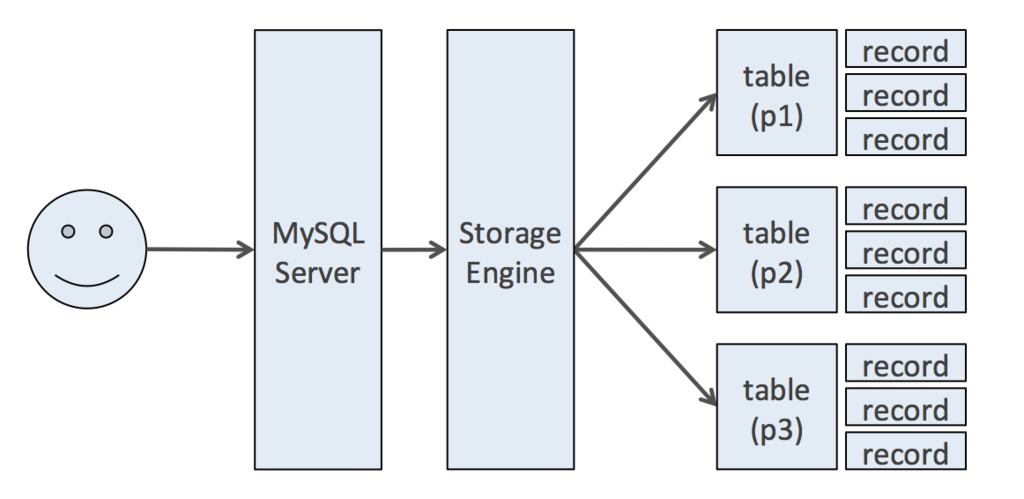
このため、例えばパーティショニングするテーブルにインデックスを張ると、各パーティションごとにインデックスが作られることになります。
パーティショニングタイプ
で、どういう基準でテーブルをパーティションに分割するのかというと、これにはいろいろな方法があります。一番有名というか、例でよく使われるのは次のような範囲による分割です。このような分割基準はパーティショニングタイプと呼ばれます。

ここでは、created_at などの日付を表現するカラムを基にパーティショニングをしているとします。このように、基本的なパーティショニングでは、特定のカラムをキーとして各レコードの配置先が決まります。パーティショニングに使うこのキーはパーティションキーと呼ばれます。
パーティションキーを基に、どこのパーティションにレコードを配置するかを決定するのがパーティション関数です。例えば、範囲に基づくパーティショニング環境下で新たに行を挿入する場合、以下のようにパーティション関数が振り分け先を判断します。
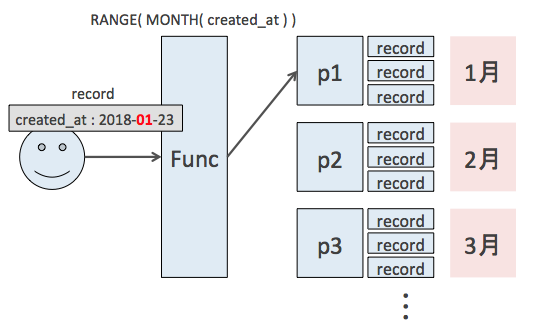
図では created_at が1月のレコードを挿入しようとしているので、パーティション関数によってそれが評価されて、1月用のパーティションへの挿入が決定されます。逆に言えば、このパーティション関数を変えればパーティション分割の基準を変えられるということです。ここでは範囲条件による分割を紹介しましたが、他にはハッシュを使ったものなどがあります。
パーティショニングのメリットやデメリット
パーティショニングの利点には幾らかありますが、ここではクエリ処理の高速化(レスポンスの向上)につながるものについて書いていきます。
パーティショニングでは前述のように、テーブルをパーティションという単位に分割します。ここで、分割されたテーブルに問い合わせが発生したことを考えます。クエリの実行時になんの工夫もしないとすると、以下のようにすべてのパーティションを検索して特定のレコードを探し出すことになるでしょう。

しかし、上のように検索条件が特定のパーティション内に閉じているのであれば、次のように、当該パーティションだけを検索するだけで済むはずです。

検索する必要のないパーティションは検索しないに越したことありません。スキャンする行数が減れば、無駄な検索処理が減り、パフォーマンスが上がります。このような仕組みはすでに実装されていて、パーティションプルーニングと呼ばれています。という感じで、パーティショニングによってスキャンの範囲を局所化できるケースでは、パフォーマンスを高められるのです。ちなみに、検索からどのパーティションを除外するのか、といった判断はオプティマイザが担当します。
インデックスを効果的に使えるクエリであれば十分高速に検索できるので、あえてこの仕組みを使った高速化を図るまでもないかもしれません。また、サマリテーブルで対応できる場合なども、あえてパーティショニングを使う必要もないということで、レスポンス高速化面でのパーティショニングの使い所は限られてくるかもしれません。
しかし、インデックスのカーディナリティが低いケースなど、テーブルスキャンが発生する場合には、検索範囲を局所化できるためパーティションプルーニングの効果は大きくなります。なので、大規模なテーブル且つカラムのカーディナリティが低いといったインデックスを貼るのが現実的でないようなケースであれば特に、パーティショニングが簡易インデックスのような形で威力を発揮します。
現在のパーティションの最大数は 8192 で、パーティションが増えれば増えるほどパーティションあたりのレコード数を減らせるので、プルーニングによる効果は大きくなります。が、プルーニングが発動しないケースではパーティション数が増えるほどオーバヘッドが大きくなります。例えばキーの範囲によってパーティショニングしている場合の行の挿入時には、オプティマイザがどのパーティションに行を挿入するかを考えることになりますが、パーティションが多いとこの作業が大変になります。
また、5.6 までは InnoDB ネイティブパーティションが導入されておらず、分割されたそれぞれのパーティションに対してハンドラ(ストレージエンジンの抽象化レイヤ)が割り当てられていました。ハンドラはメモリリソースを食うので、パーティションが増えると線形的にメモリ消費量が増加し、パフォーマンスの低下に繋がる可能性があります(5.7 からはネイティブパーティション機能が導入され、単一のハンドラで一元管理するようになっているのでこの問題は回避できる模様) 。
ということで、パーティションは増え過ぎもよろしくないので、適度な数に抑えたほうが良さげです。CPU のコアが沢山あれば並列処理である程度はカバーできるかもしれませんが。
で、パーティションプルーニングは、WHERE 句でパーティションキーが指定されないと発動しません。このため、パーティショニングされたテーブルにクエリする際には、パーティションプルーニングを発動するために一見無駄だと思われる WHERE 句を意図的に追加したり、パーティショニングが上手く効くように条件を書き換えたりしたほうがいいことがあります。それから、結合時のWHERE条件にパーティションキーが指定された時にもプルーニングは発動します。なので、結合時にも、上手く条件を指定してあげれば結合対象のテーブルが小さくなり、NLJ のコストを抑えられます。プルーニングが効かなければ前述のようなマイナス面を喰らうだけなので、こんな感じでクエリを最適化した方がよさそうです。
また、パーティショニングは 5.6 5.1 (コメントでご指摘を頂きました)から追加された機能ですが、5.7まではパーティショニングされたテーブルに対しては ICP(詳しくはこちらの記事で紹介しています)が効かず、プルーニングに失敗した場合のダメージが大きくなりそうなので、よく注意したほうがいいかもしれません(大量の行フェッチが発生する可能性があります)。5.7 以降はパーティショニングされたテーブルに対しても ICP が効きます。
おわり
パーティショニングは他の技術と同様に、とりあえずやっておけば高速化できるというような銀の弾丸ではありません。なので、その仕組みをある程度理解しておいて、適切な状況で活用することが大事ですね。よく言われているのは、パーティショニングが威力を発揮できる状況は主に超大規模なテーブルを扱う場合、ということです。
また、結局のところ、パーティショニングによる高速化が成功するかどうかはテーブルの構造やレコード数といった要因だけでなく、クエリにも大きく依存します。なので、パーティショニングを検討する場合にはクエリについてもよく分析すべきということですね。おわり。