MySQLのストレージエンジンを自作してみる
MySQL のストレージエンジン(SE)を自作してみたときのメモ。バージョンは 8.0.13。
アーキテクチャをざっくりと掴むことが目的なので、ストレージエンジンの自作といっても非常に単純な操作しかできないものです。 RDB らしさとも言えるインデックスや行レベルロック、トランザクションなどの高度な処理は実装せず、簡単に入出力の流れを追っていきます。
ゴールは以下の基本的な機能を実現して、「あ、こんなもんなんだ〜」感を覚えることです。
- CREATE 文でテーブルの作成
- INSERT 文で行の挿入
- SELECT 文で行の取得
ちなみに MySQL のコードは C/C++ です。(といっても、テンプレート等の C++ らしい拡張的な機能は使われておらず、ほぼ C で書かれています。クラスは頻繁に使われているので、俗に「クラスのあるC」なんて言われている模様。そのため、C をある程度理解していれば C++ をあまり知らなくてもなんとなーく読めるという印象。)
以降、大雑把に「ストレージエンジンとその実装の概要」「環境構築」「実装」という構成になっています。
ストレージエンジンとその実装の概要
実装に入る前に、まずはざっくり概要を把握しておきます。
前提として MySQL では、オプティマイズやクライアントとの通信を担うサーバの本体機能と、実際のデータアクセスを提供する機能が分離されています。後者がストレージエンジンなわけですが、これがプラガブルになっていることで、アプリケーションのユースケースに合わせてデータアクセスを最適化できるようになっています。例えば、以下の図のデータ部がディスクであってもメモリであっても、はたまたネットワーク越しのデータアクセスであっても、その違いはストレージエンジンレイヤで吸収されることになります。

で、このストレージエンジンの実態は、 handler クラスのオブジェクトです。 厳密に言えば、handler クラスを継承したクラスのオブジェクトです。 この継承元の handler クラスはストレージエンジンのベースクラスとして、MySQL サーバがデータアクセス時に使う API を定義します。 handler を継承して、定義された API を実装したクラスがストレージエンジン層そのものということになります。 MySQL サーバはデータ操作時、ハンドラに対して関数(API)を呼び出すだけなので、実際にどこにデータが入っているのか、どのようにデータにアクセスするのかを意識する必要がありません。 (この記事では、下の図での中間層を「ハンドラ」と総称します。ベースクラスとしての handler に焦点を当てる場合には「handler」と書きます。)

上の図の hoge_handler や piyo_handler といったクラスが各ストレージエンジンの実態です。 API の具体例としては例えば、テーブルを作成/開閉するための関数や、行を読み書きするための関数などがあります。API は handler で色々定義されていますが、ストレージエンジンは必要なものだけを実装すれば OK です。今回作るのは超単純にファイルへの読み書きをするだけのストレージエンジンなので、必要最小限の実装をしていきます。
それから、ハンドラとテーブルの関係を簡単に書いておくと、基本的にハンドラはスレッドがテーブルを開く度に生成されます。 ので、ハンドラとテーブルは多対1の関係になります。 複数のクライアントが同時にテーブルにアクセスするようなケースでは、ハンドラはその数だけ用意されるということです。
また、ハンドラの他に handlerton というストレージエンジンの種類に対して1対1になるようなオブジェクトもあります(handler + singleton で handlerton らしい)。 例えば Hoge ストレージエンジンというものがあった時に、hoge_handler クラスのインスタンスは沢山存在することになりますが、hoge_handlerton のインスタンスは常に1つです。 ハンドラがテーブル単位の操作を請け負うのに対して、handlerton はストレージエンジン単位の操作を担います(コミットやロールバックなど)。 テーブルが開かれる時にハンドラオブジェクトを作るのも handlerton の重要な役割です。
ということで、ストレージエンジン自作の基本は、handler を継承したクラスの実装と、handlerton の実装ということになります。
環境構築
大雑把に書いていきます。
ソースの準備とインストール
まずはソースをダウンロード、解凍して、
cmake -DWITH_DEBUG=1 -DDOWNLOAD_BOOST=1 -DWITH_BOOST=/tmp/boost make sudo make install
でインストールし、起動確認とrootパスワード等の初期設定をします。
自作ストレージエンジン用ファイルの準備
ストレージエンジンはソースの storage/ 配下に置かれています。 その中に EXAMPLE ストレージエンジンというチュートリアル用のストレージエンジンが用意されているので、今回はこれをベースにして新しいストレージエンジンを作っていきます。
cp -R storage/example storage/hoge
ここでは新しいストレージエンジンの名前を hoge にしていますが、好きなものでOKです(以下、hoge以外にした場合には適宜読み替えが必要)。
コピーしただけではファイル名やファイル内でストレージエンジン名を使用する箇所が "example" や "EXAMPLE" になっている状態なので、新しいストレージエンジン用に修正していきます。 まずは Makefile を開いて、"example" というワードを "hoge" に置換します。 次に CMakeListsを開いて、"EXAMPLE" → "HOGE"、"example" → "hoge" に置換します。 また、ha_example.cc および ha_example.h というファイルはそれぞれ ha_hoge.cc、ha_hoge.h にリネームします。 この2つのファイルも同様に、ファイル内の "example" → "hoge"、 "EXAMPLE" → "HOGE"、"Example" → "Hoge" と置換します。
最後に、修正を反映させるためにまた make します。
cmake -DWITH_DEBUG=1 -DDOWNLOAD_BOOST=1 -DWITH_BOOST=/tmp/boost make
これで hoge ストレージエンジンがとりあえず動くところまで来ました。 とは言ってもコピー元の EXAMPLE ストレージエンジンは何も機能が実装されていないただのテンプレートなので、クエリの処理などはまだできません。
ストレージエンジンの導入
ストレージエンジンは MySQL のプラグインとして導入されます。 なのでまず、MySQL がプラグインを認識してくれるディレクトリ、つまりストレージエンジンの配置先ディレクトリを見つける必要があります。 MySQL に接続して、以下のコマンドを送ります。
SHOW VARIABLES LIKE '%plugin_dir%';
すると配置先が表示されるので、ここにコンパイルしたストレージエンジンファイルをコピーします。 デフォルトだと配置先は /lib/plugin だと思いますが、plugin ディレクトリは作成しないと無いので作っておきます。 コピー元のストレージエンジンの実態ファイルは /plugin_output_directory/ha_hoge.so です。
で、最後にプラグインのインストールコマンドを打ってストレージエンジンをインストールします。
INSTALL PLUGIN hoge SONAME 'ha_hoge.so';
SHOW ENGINES; でちゃんと導入されたかを確認できます。
ついでに、あとで使うテスト用データベースを作っておきます。
CREATE DATABASE db_test;
これで一通りの準備はできました。 次は実装に入ります。
実装
機能を実装するために、ハンドラである ha_hoge.h、ha_hoge.cc を修正していきます。 今回は、CSV ストレージエンジンを参考にしながら、超単純なファイルの入出力をするストレージエンジンを実装します。
実装する機能としては、ざっくりと以下のような感じです。
- テーブルの作成
- テーブルのオープン
- 行の挿入
- 行の取得
- テーブルのクローズ
ハンドラの生成
上の方でも少し書きましたが、ハンドラを動かすためにはまず handlerton がそのハンドラを生成しなければいけません。 コピー元の EXAMPLE ストレージエンジンでは既に最低限の実装はされているのですが、一応その辺の流れを先に見ておきます。
ハンドラ生成の大雑把な流れとして、まず mysqld の起動時に各ストレージエンジンの handlerton が生成されます。 すべからく hoge ストレージエンジンの handlerton もこのタイミングで生成・初期化されることになります。 で、hoge_handlerton の初期化は ha_hoge.cc の hoge_init_func() という関数が行います。 そこでは handlerton 構造体の色々なメンバを設定したりしますが、特に大事なのは以下のハンドラ生成関数の登録です。
hoge_hton->create = hoge_create_handler;
hoge_hton が handlerton 構造体で、hoge_create_handler が実際にハンドラを生成する関数です。 ハンドラの生成が必要になった時には、そのテーブル(≒ストレージエンジン)の handlerton の create が呼ばれることになっています。 つまり上のコードは、hoge ストレージエンジンがハンドラを生成する際には hoge_create_handler を使ってくださいという指定になります。 で、hoge_create_handler の中身を見てみると、以下のようにただコンストラクタを呼んでオブジェクトを生成しているだけだとわかります。
static handler *hoge_create_handler(handlerton *hton, TABLE_SHARE *table, bool, MEM_ROOT *mem_root) { return new (mem_root) ha_hoge(hton, table); }
ということで、ハンドラは handlerton に登録した関数によって生成されるので、handlerton の初期化関数内でちゃんとその関数を登録してあげましょうということです。
テーブルの作成(CREATE)
ようやくコーディング。 まずは CREATE TABLE 文を処理する機能を作ります。 handler の create() がテーブルの作成時に呼び出される関数です(上に書いた handlerton の create とは別物です)。 今回作るのはファイルへの入出力をするストレージエンジンなので、データの保存先はファイルです。 なので、このストレージエンジンの create() でやるべきことは、テーブルデータ用のファイルを作成することです。
int ha_hoge::create(const char *name, TABLE *, HA_CREATE_INFO *, dd::Table *) { DBUG_ENTER("ha_hoge::create"); File table_file; if((table_file = my_create(name, 0, O_RDWR, MYF(0))) < 0) // テーブルデータファイルの作成 DBUG_RETURN(-1); if((my_close(table_file, MYF(0))) < 0) DBUG_RETURN(-1); DBUG_RETURN(0); }
my_create() や my_close() という関数がありますが、これはシステムコールのラップ関数です(ファイル作成のシステムコールは creat() ですが MySQL ではしっかりと my_create() になっていますね)。 恐らく移植性のためでしょうが、MySQL の開発では直接素のシステムコールは呼ばずにラッパーを使うようです。 通常のシステムコールに比べて一つ引数が増えていますが、これは処理に失敗した場合の動作などを指定するものです。
ちなみに、「my_○○系」を更にラップした「mysql_file_○○」という関数(マクロ)もあります。 これらは多分 PSI(Performance Schema Instrumentation) というデータベース動作の計測用に用意されたものです。 試していませんが、MySQL で計測オプションが有効になっているとこれらの計測系プログラムがシステムコールレベルの動作まで計測してくれるっぽいですね(勿論パフォーマンスに影響ありでしょうが)。
少し脱線したので本筋に戻って、動作確認のために上のコードをまた make して反映させてから、以下のコマンドを送ってみます。
CREATE TABLE ta_test (col1 CHAR(100), col2 CHAR(100)) ENGINE=hoge;
そうすると、データディレクトリの db_test 配下に、ta_test というファイルができているはずです。 ta_test.sdi というファイルも一緒に作られますが、こちらにはカラム定義や使用するストレージエンジンなどのメタデータ系の情報が書かれています(MySQL8 より前の frm ファイルに近い?)。
ちなみに上の実装は、テーブル作成時のオプション等はガン無視する仕様になっています。 今回はそこまで作り込みませんが、しっかりとしたストレージエンジンを作るのであれば、そういったオプションへの対応もこの関数内で必要になってくるでしょう。 その場合は、テーブル作成に関する情報が入っている第三引数をよしなに捌く感じになりそうです。
テーブルのオープン
テーブルデータを操作する機能を実装する前に、それらの機能の前処理として必要になるテーブルのオープンを実装します。 handler クラスの open() がテーブルのオープンを担当する関数です。 今回は create() で作成されたデータファイルを開いて、ファイルディスクリプタを取得することをオープン処理とします。 ので、handler にそれを保持する変数を用意しておきます。 こいつは後々 SELECT 文での行読み取りなんかで使います。
class ha_hoge : public handler { ~~ File data_file; // データファイルのディスクリプタ ~~
以下 open() の実装です。
int ha_hoge::open(const char *name, int, uint, const dd::Table *) { DBUG_ENTER("ha_hoge::open"); if (!(share = get_share(name))) DBUG_RETURN(1); // Hoge_share の取得 thr_lock_data_init(&share->lock, &lock, NULL); // ロックオブジェクトの初期化 if ((data_file = my_open(share->data_file_name, O_RDONLY, MYF(0))) == -1){ // ファイルのオープン close(); DBUG_RETURN(-1); }; DBUG_RETURN(0); }
第一引数の name にはオープンするテーブルの名前が入ってきます。 上のコードではまず、get_share() を呼び出して自インスタンスの share に代入しています。 share は Hoge_share クラスの変数で、Hoge_share は Handler_share を継承したクラスです。 この Hoge_share はテーブル操作についての共通情報や関数などを持っているオブジェクトで、すべての hoge ハンドラインスタンスが共有します。 こいつに何を持たせるかはストレージエンジン次第ですが、ここでは後で使うためにデータファイル名を持たせておきます。 以下 Hoge_share の実装です。
class Hoge_share : public Handler_share { public: THR_LOCK lock; Hoge_share(); ~Hoge_share() { thr_lock_delete(&lock); } const char *data_file_name; // データファイル名 };
で、この Hoge_share を取得するための get_share() 関数の実装が以下。
Hoge_share *ha_hoge::get_share(const char *table_name) { Hoge_share *tmp_share; DBUG_ENTER("ha_hoge::get_share()"); lock_shared_ha_data(); // Hoge_share のロック if (!(tmp_share = static_cast<Hoge_share *>(get_ha_share_ptr()))) { // 既に Hoge_share インスタンスが存在すればそれを取得 tmp_share = new Hoge_share; // インスタンスがなければ新規生成 tmp_share->data_file_name = table_name; tmp_share->write_opened = false; set_ha_share_ptr(static_cast<Handler_share *>(tmp_share)); // 生成したインスタンスをシングルトンとして登録 } unlock_shared_ha_data(); // Hoge_share へのロックの解放 DBUG_RETURN(tmp_share); }
lock_shared_ha_data() は、Hoge_share の競合をプロテクトするためにロックをかける関数です。 Hoge_share はシングルトンである必要があるので、複数のハンドラが同時にこれを生成したりしないようにしています。 get_ha_share_ptr() は既に存在する Hoge_share が存在すればそれを返す関数で、まだ生成されていなければ if 文に入って生成・初期化します。 このタイミングで引数で取ったテーブル名を、Hoge_share->data_file_name に入れておきます。 生成後、set_ha_share_ptr() でシングルトンインスタンスとして登録することで、次回以降の get_share() ではそれが返るようになります。
これでオープン処理の実装は終わりです。
データの挿入(INSERT)
次は、INSERT 文で指定された文字列をデータファイルに追記する処理を実装します。 INSERT 文に対応する API は write_row() です。 例えば以下の文を実行した時に、データファイルに「"piyo","hugahuga"\n」と書き込まれるのがゴールです(このファイル内でのフォーマットは何でもいいのですが、わかりやすそうな CSV 形式にします)。
INSERT INTO ta_test VALUES("piyo", "hugahuga");
まず準備として、ファイル書き込み用のファイルディスクリプタを生成する関数を作っておきます。 書き込み用ファイルディスクリプタはストレージエンジンに1つだけあればいいので、ハンドラ間で共有できるように Hoge_share に持たせます。
class Hoge_share : public Handler_share { public: ~~ File write_filedes; // データファイルの書き込み用ディスクリプタ bool write_opened; ~~ };
で、以下の関数で share->write_filedes をセットします。
int ha_hoge::init_writer() { DBUG_ENTER("ha_hoge::init_writer"); if ((share->write_filedes = my_open(share->data_file_name, O_RDWR | O_APPEND, MYF(0))) == -1) { // 書き込み用ファイルディスクリプタのセット DBUG_RETURN(-1); } share->write_opened = true; DBUG_RETURN(0); }
それから、文字列書き込みの際に使うバッファをハンドラに用意しておきます(実際にはこのバッファは読み込み処理でも使う汎用バッファです)。以下の String クラスは、string.h の String ではなく、include/sql_string.h の String クラスです。
class ha_hoge : public handler { ~~ String buffer; ~~
で、write_row() の実装が以下です。
int ha_hoge::write_row(uchar *) { DBUG_ENTER("ha_hoge::write_row"); int size; ha_statistic_increment(&System_status_var::ha_write_count); if (!share->write_opened) if (init_writer()) DBUG_RETURN(-1); size = encode_quote(); // バッファへのクエリ文字列格納とバッファサイズの取得 if ((my_write(share->write_filedes, (uchar *) buffer.ptr(), size, MYF(0))) < 0) // データファイルへの書き込み DBUG_RETURN(-1); stats.records++; DBUG_RETURN(0); }
統計情報更新等の処理も一応書いてみましたが、本筋としてやっていることは単純で、クエリで指定された文字列を整形して、データファイルに書き込んでいるだけです。 my_write() では、init_writer() で用意したディスクリプタに対して、buffer が格納している文字列を、size 分だけ書き込みます。
書き込む内容である buffer の中身をいつセットしているんだという話になりますが、これは encode_quote() 内でやっています。 encode_quote() はクエリで受け取った文字列を CSV 形式で buffer にまとめて、そのサイズを返します。 上に書いた INSERT 文の例では、buffer に「"piyo","hugahuga"\n」を格納し、その終端を表すためにサイズを返すのがこの関数のゴールです。 以下その実装です。
int ha_hoge::encode_quote() { char attribute_buffer[1024]; String attribute(attribute_buffer, sizeof(attribute_buffer), &my_charset_bin); my_bitmap_map *org_bitmap = tmp_use_all_columns(table, table->read_set); // カラム情報の読み取りフラグを立てる buffer.length(0); // buffer を初期化 for (Field **field = table->field; *field; field++) { const char *p; const char *end; (*field)->val_str(&attribute, &attribute); // クエリ文字列の実際の長さを attribute に格納 p = attribute.ptr(); // 書き込む文字列の先頭にポインタをセット end = attribute.length() + p; // 書き込む文字列の終端にポインタをセット buffer.append('"'); for (; p < end; p++) buffer.append(*p); buffer.append('"'); buffer.append(','); } buffer.length(buffer.length() - 1); buffer.append('\n'); tmp_restore_column_map(table->read_set, org_bitmap); // 読み取りフラグを寝かせる return (buffer.length()); }
まず、tmp_use_all_columns() でカラム情報を読み取るためのフラグを立てています。 これを立てておかないと、後で field 変数から情報を取得する際にアサーションで落ちてしまいます。 で、クエリで受け取った文字列は、table->field の配列で管理されていて、例えば2カラムへの挿入の場合には field[0] と field[1] にそれぞれの値が格納されてきます。 つまり上の INSERT クエリの場合には field[0] に "piyo"、field[1] に "hugahuga" が入ってくるイメージです。 なので、for ループを回してそれぞれのカラムを処理していきます。 ここで厄介なのは、各 field に格納されている値は末尾に大量のスペースが入っていることです。 つまり、ポインタを進めながら field[0] の値を1文字ずつ buffer に入れていく際に、どこまでが field[0] の実際の値なのか判断する必要があります。 で、この辺の判断は (*field)->val_str() がやっていて、引数で渡している attribute に、挿入すべき文字列の長さ(=文字列の終端)を格納しています。 この長さは attribute.length() + p で end 変数に格納され、次の for ループの終了条件になります。 その for ループでは、ポインタを進めながらループで buffer を埋めていき、最終的に buffer には「"piyo","hugahuga"\n」という文字列が格納されます。
この実装だと TABLE 構造体 と Field クラスのインクルードが必要なので、ha_hoge.cc に追記します。
#include "sql/table.h" #include "sql/field.h"
変更を反映させてから先程の INSERT 文を実行すると、ta_test に文字列が追記されているはずです。 これでとりあえずの INSERT 処理は実装できました。
テーブルスキャン
テーブルの作成やオープンはそれぞれに対応する関数を一つ実装するだけでしたが、テーブルスキャンでは複数の関数の実装が必要になります。 以下は CSV ストレージエンジンが5行取得する際の関数コールの流れですが、眺めてみるとなんとなくテーブルスキャンの流れを掴めると思います。
ha_tina::store_lock ha_tina::external_lock ha_tina::info ha_tina::rnd_init ha_tina::extra - ENUM HA_EXTRA_CACHE Cache record in HA_rrnd() ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::extra - ENUM HA_EXTRA_NO_CACHE End caching of records (def) ha_tina::external_lock ha_tina::extra - ENUM HA_EXTRA_RESET Reset database to after open
つまり実装が必要なのは、
- store_lock()
- 内部ロック
- external_lock()
- 外部ロックなど
- info()
- 最適化情報の設定
- rnd_init()
- テーブルスキャンの準備
- extra()
- ヒントの設定
- rnd_next()
- 行の読み取り
の6つです。
store_lock()
レコードの読み書きにあたって、MySQL サーバがロックを取得しようとした時に呼び出される関数です。 MySQL サーバ側のロックロジックでは、取得時にこの store_lock() を呼び出すことで、ストレージエンジン側にもロックの裁量を与えているみたいです。 store_lock() の中で、MySQL サーバ側で判断したロック種別をストレージエンジンに合わせたものに変更できるようにしているみたいですが、今回は細かいロック機構を実装するつもりはありませんし、ぶっちゃけどんな状況でこのロックの変更が必要になるのか不明なので変更しないでおきます(一切ロックを提供しないストレージエンジンではここに何も書かないとかになりそう)。
THR_LOCK_DATA **ha_hoge::store_lock(THD *, THR_LOCK_DATA **to,
enum thr_lock_type lock_type) {
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK) lock.type = lock_type;
*to++ = &lock;
return to;
}
external_lock()
外部ロックのためのフックです。 外部ロックは簡単に言えば、テーブルデータファイルへのファイルロックのことです。 複数の MySQL サーバが単一のデータファイルを弄る場合なんかで競合を回避するために外部ロックが必要になります。 トランザクショナルなストレージエンジンでは、ロールバック等のためにステートメントの開始と終了をこの関数で検出するような使われ方もするみたいですが、この用法についてはコメントで "abused" と表現されています。 とりあえず今回は関係ない関数なので、デフォルトの 0 を返すだけの実装でいきます。
int ha_hoge::external_lock(THD *, int) { DBUG_ENTER("ha_hoge::external_lock"); DBUG_RETURN(0); }
rnd_init()
テーブルスキャンのための準備をする関数です。 データファイル内をトレースするためのポジション情報やレコード数情報を初期化しておきます。
int ha_hoge::rnd_init(bool) { DBUG_ENTER("ha_hoge::rnd_init"); current_position = 0; stats.records = 0; DBUG_RETURN(0); }
ポジション情報はハンドラに持たせておきます。
class ha_hoge : public handler { ~~ off_t current_position; ~~
info()
最適化のためにオプティマイザが使う統計情報などを設定する関数です。 ちなみに SHOW TABLES STATUS の結果は、ここで設定された情報が基になっているようです。 例によって細かい実装はしませんが、以下のコードだけ入れておきます。
int ha_hoge::info(uint) {
DBUG_ENTER("ha_hoge::info");
if (stats.records < 2)
stats.records= 2;
DBUG_RETURN(0);
}
コメントによればレコード数が0もしくは1の場合と、2以上の場合とで、オプティマイザの処理が変わるみたいで、前者だとテーブルスキャンの時に全部のレコードが読まれない可能性があるっぽいです(詳しいことはわかりません)。 ので、とりあえず2以上の値を返しておく感じで。
extra()
MySQL サーバ側からストレージエンジンの動作に対してヒントを送るための関数らしいですが、これも拡張的というか応用的な機能なのでスルーします。 操作するファイルの種類に応じてスキャン動作を変えたりする時なんかに必要なのかもしれません。
int ha_hoge::extra(enum ha_extra_function) { DBUG_ENTER("ha_hoge::extra"); DBUG_RETURN(0); }
rnd_next()
やっとですが、この rnd_next() がデータファイルから実際にレコードを読み取る関数です。 テーブルスキャンは、終了条件を満たすまでこいつが呼ばれ続ける形で行われます。 イメージとしては、1行読み取る度に1回この関数が呼ばれる感じです。 基本的には、ファイルカーソルが EOF に達した時に HA_ERR_END_OF_FILE を返して処理を終了してあげるのが正常な動作です。 終了条件は自由に設定できますが、今回はとりあえず EOF まで読んでいくだけの実装をしてみます。
以下、rnd_next() の実装です。
int ha_hoge::rnd_next(uchar *buf) { DBUG_ENTER("ha_hoge::rnd_next"); ha_statistic_increment(&System_status_var::ha_read_rnd_next_count); int error = find_current_row(buf); // レコードを buf に格納 if(!error) stats.records++; DBUG_RETURN(error); }
引数の buf がファイルから読み取ったレコードを格納する先です。 MySQL サーバの視点で見ると、ストレージエンジンの rnd_next() を繰り返してレコードを buf に格納してもらい、結果をクライアントに返す形になっています。 で、上のコードでは実際の行読み取りは find_current_row() に任せていて、rnd_next() 内では大枠の処理だけ書いています。
やや長めですが、以下が その find_current_row() の実装です。
int ha_hoge::find_current_row(uchar *buf) { DBUG_ENTER("ha_hoge::find_current_row"); my_bitmap_map *org_bitmap; uchar read_buf[IO_SIZE]; bool is_end_quote; uchar *p; uchar current_char; uint bytes_read; memset(buf, 0, table->s->null_bytes); // NULL指定ビットマップの初期化 org_bitmap = tmp_use_all_columns(table, table->write_set); // 書き込み用ビットを立てる for (Field **field = table->field; *field; field++) { bytes_read = my_pread(data_file, read_buf, sizeof(read_buf), current_position, MYF(0)); // read_bufにファイルの行を読み込む if (!bytes_read){ // ファイルを読み終わったら tmp_restore_column_map(table->write_set, org_bitmap); DBUG_RETURN(HA_ERR_END_OF_FILE); } p = read_buf; current_char = *p; buffer.length(0); is_end_quote = false; for(;;){ // buffer に読み取った行を詰める if (current_char == '"') { if (is_end_quote) { current_position += 2; break; } is_end_quote = true; } else { buffer.append(current_char); } current_char = *++p; current_position++; } (*field)->store(buffer.ptr(), buffer.length(), buffer.charset()); // buffer の内容を buf に格納する } tmp_restore_column_map(table->write_set, org_bitmap); // 書き込みビットを寝かせる DBUG_RETURN(0); // まだ行が存在するので0を返して処理を継続させる }
memset() では buf の先頭を0で埋めています。 これは、MySQL レコードの内部フォーマットの先頭がカラム数分の NULL 指示ビットマップだからです(カラムの内容はその後に続きます)。 NULL 指示ビットマップは、それに対応するレコードの内容が NULL であることを明示するための仕組みです。 今回はカラムに NULL が入ることを想定しないので、memset() ではこのビットマップ部分をすべて0に設定しているわけです。 ビットマップ部分の大きさ(バイト単位なので、今回のように2カラムの場合には1バイト)は table->s->null_bytes に入っているので、memset() で0を埋めるサイズの指定にはこれを使います。 また、固定長カラムの場合にはビットマップの先頭に NULL 指示とは関係のない開始ビットが付加されます。 つまり、今回のように CHAR のカラムを2つ用意した場合の挙動は以下のようになります。
memset(buf, 0x01, table->s->null_bytes); // 0x01 は開始ビットなので変更しない memset(buf, 0x02, table->s->null_bytes); // 右から2番目のビットを立てる = col1 が NULL として結果が返される memset(buf, 0x04, table->s->null_bytes); // 右から3番目のビットを立てる = col2 が NULL として結果が返される
カラム値に NULL を許可するストレージエンジンでは、この辺りをうまく調整して NULL を表現できるように実装する必要があります。
tmp_use_all_columns() でやっていることは、table->write_set に書き込み用のフラグを立てることです。 これを立てておかないと後々 buf に書き込むときにアサーションエラーになります。
次に、その次の行の for ループを table->field で回します(カラム数文回ります)。 Field は各カラム情報を表現するクラスで、実際のデータを保持するのは ptr というメンバです(カラムデータのインメモリコピーと言えます)。 で、読み取ったカラムデータを buf に入れてあげるのが rnd_next() の役割な訳ですが、実はループ内での field->ptr は buf と同じ場所を指しています。 したがって、後半の (*field)->store() で field->ptr にデータを格納してあげることで、それが buf にも入ることになります。 find_current_row() 内にレコードデータを buf に格納しているコードが存在しないのはこのためです。 要するに、field から間接的に buf を扱っている形になります。
ファイルからのレコード読み取り処理ロジックは、pread() で read_buf に読み込んだ行を1文字ずつ buffer に格納しているだけの単純なものです。 ただ、find_current_row() は各行に対して呼ばれるので、複数行を読み取る場合には「現在どこの行まで読んだか」を記録しておく必要があります。 これは current_position で管理していて、文字を読む度にカウントしています。
以上が読み取り処理の実装になります。 コンパイルして以下のクエリを送ると、INSERT で格納したデータがしっかりと返っくるはずです。
SELECT * FROM ta_test;
おわり
ということで、ストレージエンジンの基本的な入出力機能を一通り実装してみました。 本格的にやろうとすると、ここから更にインデクシングやロッキングなどの高度な機能が必要になりますが、とりあえずこれだけでもストレージエンジンの概要はざっくりと掴めた気がします。 謎のビルドエラーでハマったりして面倒臭さが強烈でしたが、気が向いたらその辺の機能もまた実装してみようかなあと思います。 おわり。
【MySQL】データベースのパーティショニングとはなんぞやという話
パーティショニングについての覚書。 一応 MySQL が前提。先に具体的な実体を書いたあと、それがパフォーマンス向上にどう寄与するのかを書きます。
パーティショニング is 何
簡単に言えば、データベースのテーブルを物理的に分割することです。テーブルのデータが分割されてしまっても、外からは論理的(透過的)に単一のテーブルとして見えます。なので、以下の図のようにクライアントや DML レイヤはそれを意識する必要はありません。p1 や p2 は分割されたパーティションを表しています。

この透過性は MySQL サーバによって提供されています。また、ストレージエンジンは分割された各パーティションを独立したテーブルのように扱います。これを図にすると次のような感じになります。
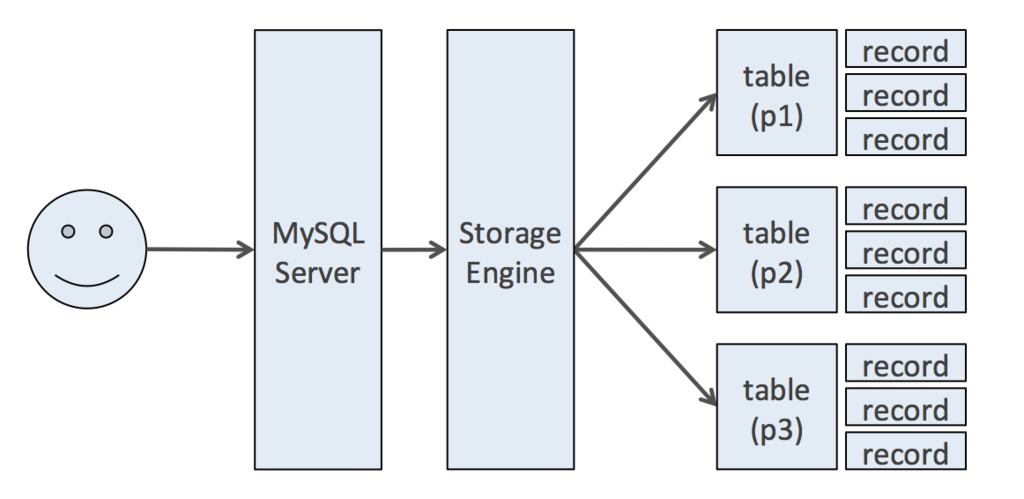
このため、例えばパーティショニングするテーブルにインデックスを張ると、各パーティションごとにインデックスが作られることになります。
パーティショニングタイプ
で、どういう基準でテーブルをパーティションに分割するのかというと、これにはいろいろな方法があります。一番有名というか、例でよく使われるのは次のような範囲による分割です。このような分割基準はパーティショニングタイプと呼ばれます。

ここでは、created_at などの日付を表現するカラムを基にパーティショニングをしているとします。このように、基本的なパーティショニングでは、特定のカラムをキーとして各レコードの配置先が決まります。パーティショニングに使うこのキーはパーティションキーと呼ばれます。
パーティションキーを基に、どこのパーティションにレコードを配置するかを決定するのがパーティション関数です。例えば、範囲に基づくパーティショニング環境下で新たに行を挿入する場合、以下のようにパーティション関数が振り分け先を判断します。
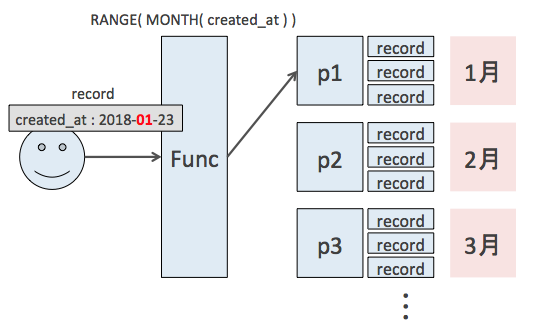
図では created_at が1月のレコードを挿入しようとしているので、パーティション関数によってそれが評価されて、1月用のパーティションへの挿入が決定されます。逆に言えば、このパーティション関数を変えればパーティション分割の基準を変えられるということです。ここでは範囲条件による分割を紹介しましたが、他にはハッシュを使ったものなどがあります。
パーティショニングのメリットやデメリット
パーティショニングの利点には幾らかありますが、ここではクエリ処理の高速化(レスポンスの向上)につながるものについて書いていきます。
パーティショニングでは前述のように、テーブルをパーティションという単位に分割します。ここで、分割されたテーブルに問い合わせが発生したことを考えます。クエリの実行時になんの工夫もしないとすると、以下のようにすべてのパーティションを検索して特定のレコードを探し出すことになるでしょう。

しかし、上のように検索条件が特定のパーティション内に閉じているのであれば、次のように、当該パーティションだけを検索するだけで済むはずです。

検索する必要のないパーティションは検索しないに越したことありません。スキャンする行数が減れば、無駄な検索処理が減り、パフォーマンスが上がります。このような仕組みはすでに実装されていて、パーティションプルーニングと呼ばれています。という感じで、パーティショニングによってスキャンの範囲を局所化できるケースでは、パフォーマンスを高められるのです。ちなみに、検索からどのパーティションを除外するのか、といった判断はオプティマイザが担当します。
インデックスを効果的に使えるクエリであれば十分高速に検索できるので、あえてこの仕組みを使った高速化を図るまでもないかもしれません。また、サマリテーブルで対応できる場合なども、あえてパーティショニングを使う必要もないということで、レスポンス高速化面でのパーティショニングの使い所は限られてくるかもしれません。
しかし、インデックスのカーディナリティが低いケースなど、テーブルスキャンが発生する場合には、検索範囲を局所化できるためパーティションプルーニングの効果は大きくなります。なので、大規模なテーブル且つカラムのカーディナリティが低いといったインデックスを貼るのが現実的でないようなケースであれば特に、パーティショニングが簡易インデックスのような形で威力を発揮します。
現在のパーティションの最大数は 8192 で、パーティションが増えれば増えるほどパーティションあたりのレコード数を減らせるので、プルーニングによる効果は大きくなります。が、プルーニングが発動しないケースではパーティション数が増えるほどオーバヘッドが大きくなります。例えばキーの範囲によってパーティショニングしている場合の行の挿入時には、オプティマイザがどのパーティションに行を挿入するかを考えることになりますが、パーティションが多いとこの作業が大変になります。
また、5.6 までは InnoDB ネイティブパーティションが導入されておらず、分割されたそれぞれのパーティションに対してハンドラ(ストレージエンジンの抽象化レイヤ)が割り当てられていました。ハンドラはメモリリソースを食うので、パーティションが増えると線形的にメモリ消費量が増加し、パフォーマンスの低下に繋がる可能性があります(5.7 からはネイティブパーティション機能が導入され、単一のハンドラで一元管理するようになっているのでこの問題は回避できる模様) 。
ということで、パーティションは増え過ぎもよろしくないので、適度な数に抑えたほうが良さげです。CPU のコアが沢山あれば並列処理である程度はカバーできるかもしれませんが。
で、パーティションプルーニングは、WHERE 句でパーティションキーが指定されないと発動しません。このため、パーティショニングされたテーブルにクエリする際には、パーティションプルーニングを発動するために一見無駄だと思われる WHERE 句を意図的に追加したり、パーティショニングが上手く効くように条件を書き換えたりしたほうがいいことがあります。それから、結合時のWHERE条件にパーティションキーが指定された時にもプルーニングは発動します。なので、結合時にも、上手く条件を指定してあげれば結合対象のテーブルが小さくなり、NLJ のコストを抑えられます。プルーニングが効かなければ前述のようなマイナス面を喰らうだけなので、こんな感じでクエリを最適化した方がよさそうです。
また、パーティショニングは 5.6 5.1 (コメントでご指摘を頂きました)から追加された機能ですが、5.7まではパーティショニングされたテーブルに対しては ICP(詳しくはこちらの記事で紹介しています)が効かず、プルーニングに失敗した場合のダメージが大きくなりそうなので、よく注意したほうがいいかもしれません(大量の行フェッチが発生する可能性があります)。5.7 以降はパーティショニングされたテーブルに対しても ICP が効きます。
おわり
パーティショニングは他の技術と同様に、とりあえずやっておけば高速化できるというような銀の弾丸ではありません。なので、その仕組みをある程度理解しておいて、適切な状況で活用することが大事ですね。よく言われているのは、パーティショニングが威力を発揮できる状況は主に超大規模なテーブルを扱う場合、ということです。
また、結局のところ、パーティショニングによる高速化が成功するかどうかはテーブルの構造やレコード数といった要因だけでなく、クエリにも大きく依存します。なので、パーティショニングを検討する場合にはクエリについてもよく分析すべきということですね。おわり。
MySQL(InnoDB)のネクストキーロックの仕組みと範囲を図解する
MySQL(InnoDB) のロックにはレコードロックとかギャップロックとかネクストキーロックとかありますが、結構ややこしくて、クエリで条件文が与えられた時にそれがどのようなロックになるのかをイメージし辛い問題が自分の中でありました。ので、実験してみた(MySQL8.0.12、REPEATABLE READ)結果を図で書き残します。なお、結果は SELECT FOR UPDATE を使って排他ロックをとる方法で試したものですが、ロックの範囲を知る上では、排他ロックか共有ロックかとかは関係ないかと思います。
前提として、以下のような id カラムのみを持つインデックスレコードへのロックを考えます。レコードには10 ~ 40 までの 5 飛びの値が存在します。それぞれのインデックスレコードの間にはギャップ(gap)が存在します。また、最初のレコードの前と最後のレコードの後には、論理的な最小値への gap と論理的なの最大値への gap が存在します(どう表現すればいいかよくわからない)。
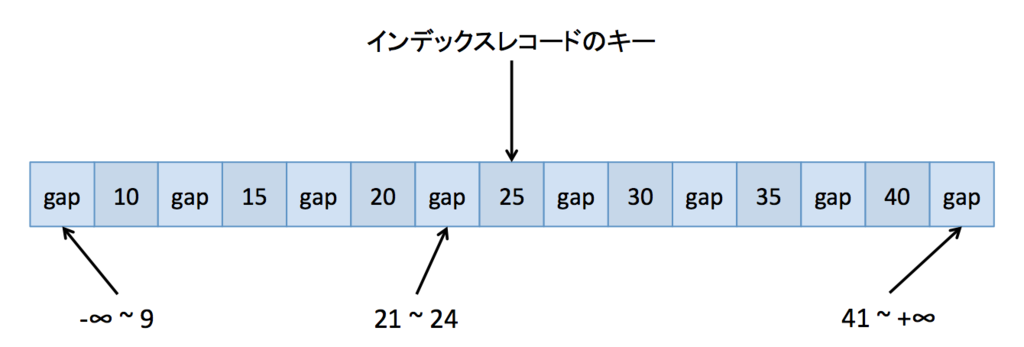
で、ここに記載のように、
とします。
MySQL(InnoDB)のロックの範囲
存在する一意なid

条件文で、存在する一意な id が指定された場合には、その id を持つインデックスレコードに対してレコードロックが発生します。なお、黒の矢印は条件文が指定するポイントを示しています。
存在しない一意なid
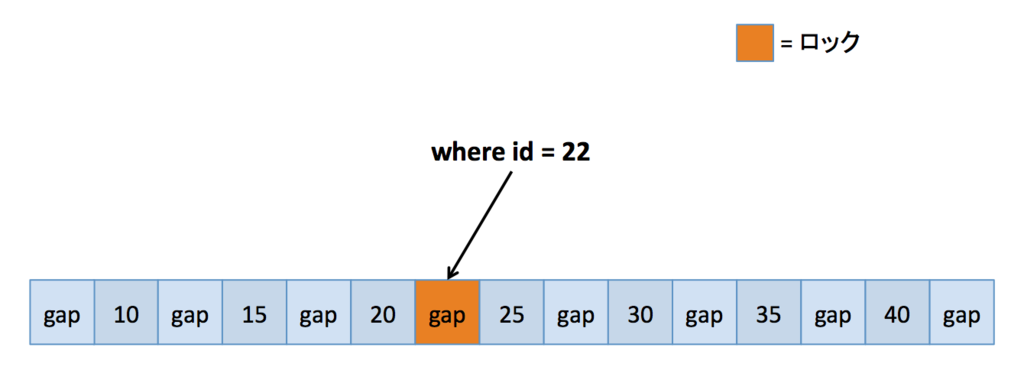
単一の id 指定時にそのレコードが存在しない場合には、その id が入るべき gap へのギャップロックが発生します。
存在しない範囲境界
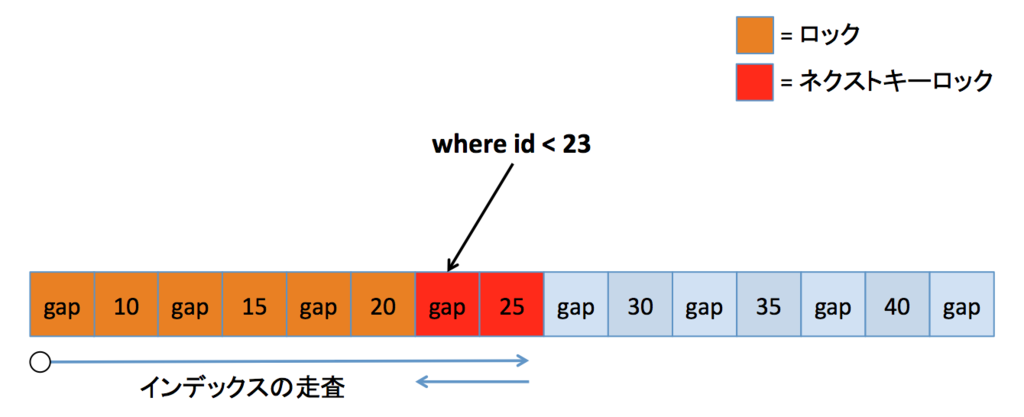
このケースでは、指定された値が入るべき gap へのギャップロックと、その次のインデックスレコードへのレコードロックが発生します。インデックスレコードへのレコードロックと、その直前の gap へのギャップロックという表現もできます。上記の定義通りですね。これがネクストキーロックの動作です。
また、ここからはイメージ的にわかりやすいよう、ロック時のインデックスの走査を図示しています(なんとなくのイメージを掴むためなので厳密性は考慮していません。例えば、gap は実際にはレコードのように実体として表現されていないはずなので、走査が gap から開始されるというのは少し変です。また、ネクストキーロック時にレコードへのロックが先か、gap へのロックが先かは定かではないです)。InnoDB のロックではそのようにインデックスを辿りながら、出会ったレコードをロックしていきます。それから、図では走査の矢印を最後だけ逆向きにしてネクストキーロックを表現していますが、多分すべての走査地点で、次のキーに進むたびに手前の gap をロック(ネクストキーロック)しているのだと思います。ですから、図では便宜上赤い部分をネクストキーロックとしていますが、実際にはすべてのロック点でこの動作が発生していそうということです。つまり、ネクストキーロックをしながら1つずつキーをスキャンしていくということです。
で、上のケースでは、25 をロックしなくても本来は OK なのですが、InnoDB ではそこまでロックしてしまいます。gap ロックをかける際には必ず次のレコードへのロックも必要なのでしょうか? しかし、「存在しない一意なid」のケースを見てみると、gap ロックを単体でかけること可能だということを示しています。このあたりはよく理解していませんが恐らく、一度インデックス走査を開始すると、次のキーを辿り、条件判定して且つロックしてからではないとその直前にある gap にロックが掛けられなくなっているのかもしれません。
まあ仮にそうだったとしたら、次のように逆向きに走査すれば 25 はロックされませんね。
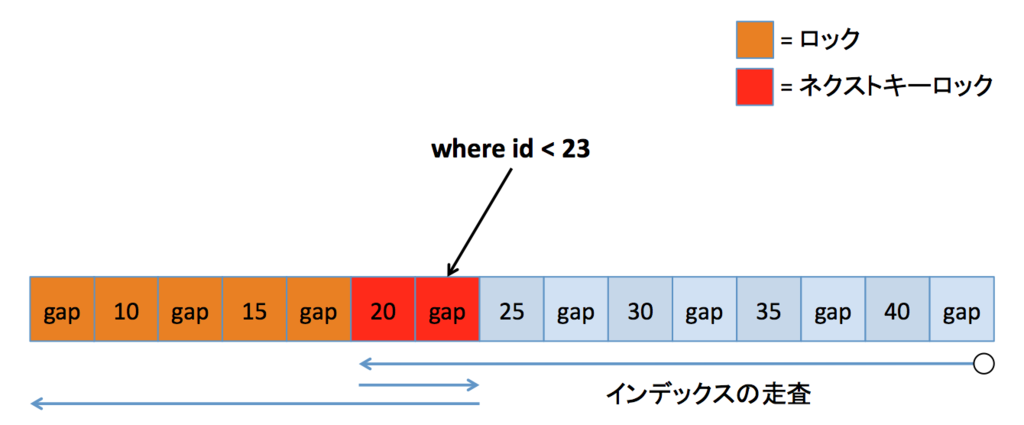
ですから、ロック時の走査は逆向きには辿れないのかもしれません。
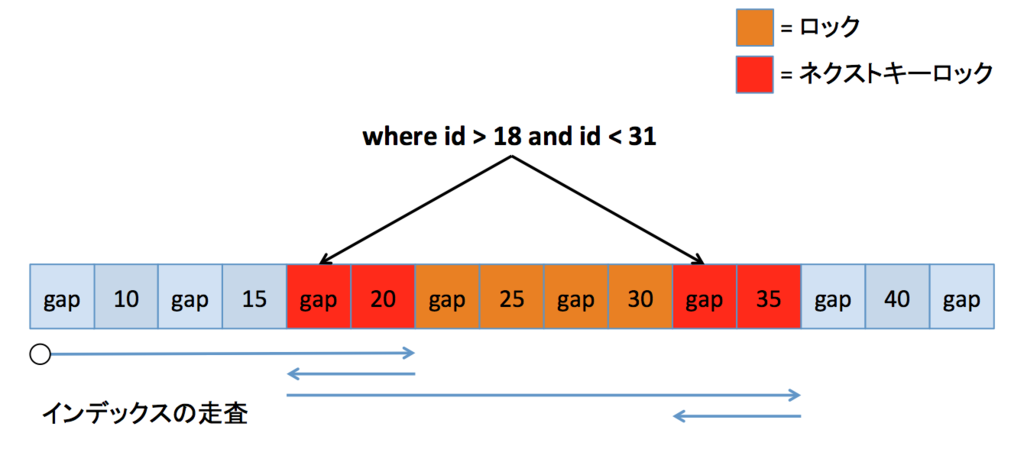
存在しない範囲境界(不等号逆版)
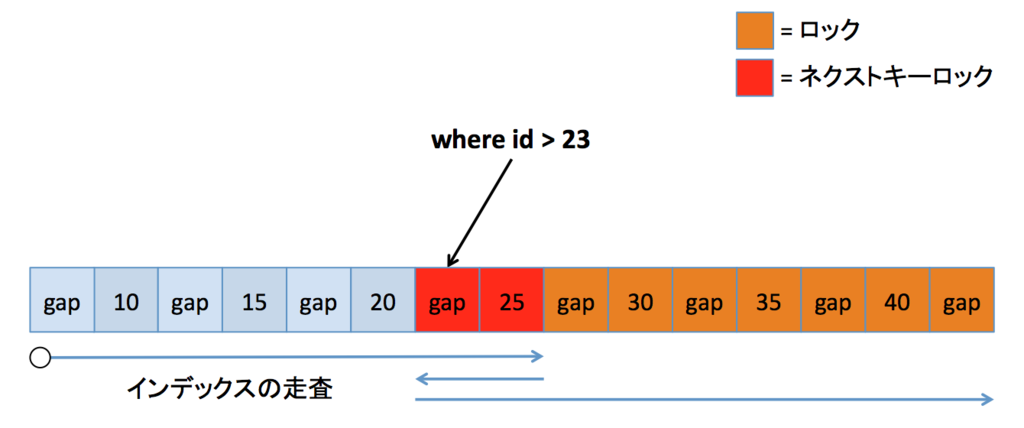
一つ前ののケースの不等号逆版です。このケースでは、20 が余分にロックされていないため、必要最小限のロックだと言えそうです(21 や 22 が余分にロックされてしまうと言えますが、MySQL では gap を分断するロックは難しい)。
ここまでのケースの動きを考えると、このケースでインデックスの走査を逆向きに辿ると 20 までロックされることになるはずです。先程の例とこの動作を考えると、やはりロック時のインデックスの走査は左から右に辿るようになっている、と推測できます。つまり何が言いたいかというと、不等号の向きによって(一つ前のケースでの 25 のような)余分なロックが発生したりしなかったりするのは、恐らくインデックスの走査の向きによるものだということです。
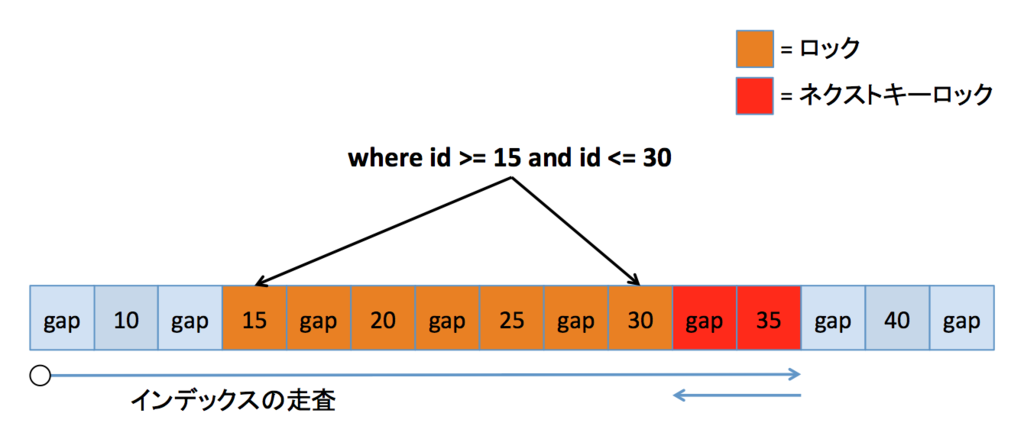
存在する範囲境界
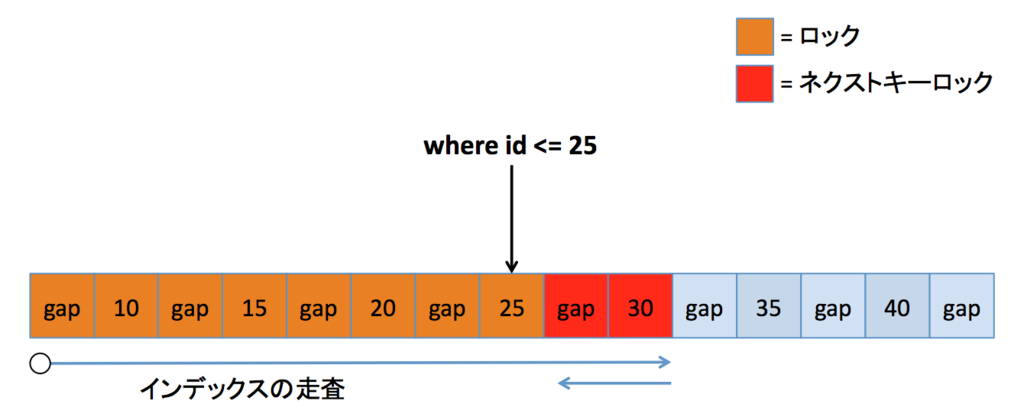
これが割と厄介だと思っています。id <= 25 という条件を普通に考えれば、25 までロックされて、その後の gap や 30 はロックされないだろうと思いがちだからです。この条件なら、本来 26 への挿入や 30 の更新は許可されるべきです。このケースの動作はかなり謎めいていますが、結果から察するに、インデックス走査の終了条件が「条件文を満たさない場合」になっているのかもしれません。そうであれば、25 まで辿ってもまだ id <= 25 という条件は満たすので、次の 30 に進み、ここで条件が満たされなくなり、ネクストキーロックによってその前の gap もロックされる、と説明できるからです。
ちなみにここでも、もし逆走できれば 30 やその前の gap はロックされないはずです。なので個人的には、ロック時のインデックスの走査は「左から右に、条件を満たさないインデックスレコードまで走る」という風に理解しておけばいいかなあと思ったりしています。
存在する範囲境界(逆版)
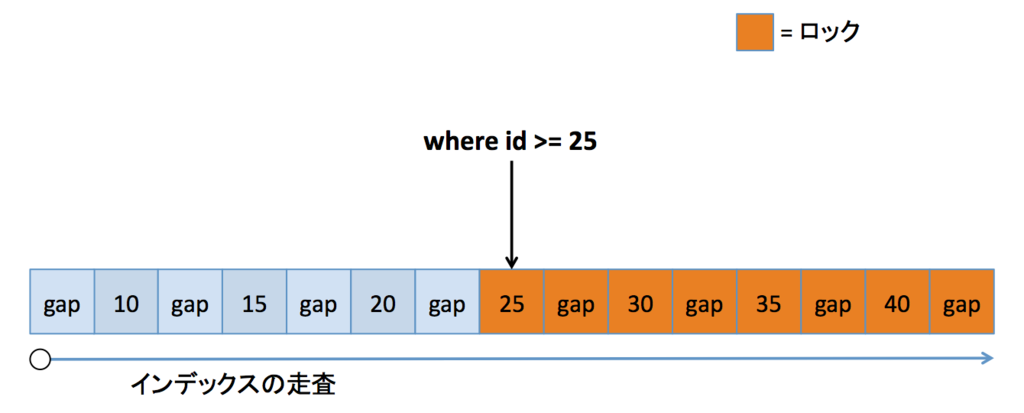
このケースでは、当該値からロックを開始します。「存在しない範囲境界(不等号逆版)」と異なり、このケースでは手前の gap をロックしません。なんでもかんでもネクストキーロックするわけではないということですね。レコードロックでスタートして、それ以降はネクストキーロックという感じでしょうか。
存在しない2点の範囲境界
これまでに書いたケースで説明できる動作になっています。
存在する2点の範囲境界
こちらもこれまでに書いたケースの組み合わせです。
範囲が分割されている場合
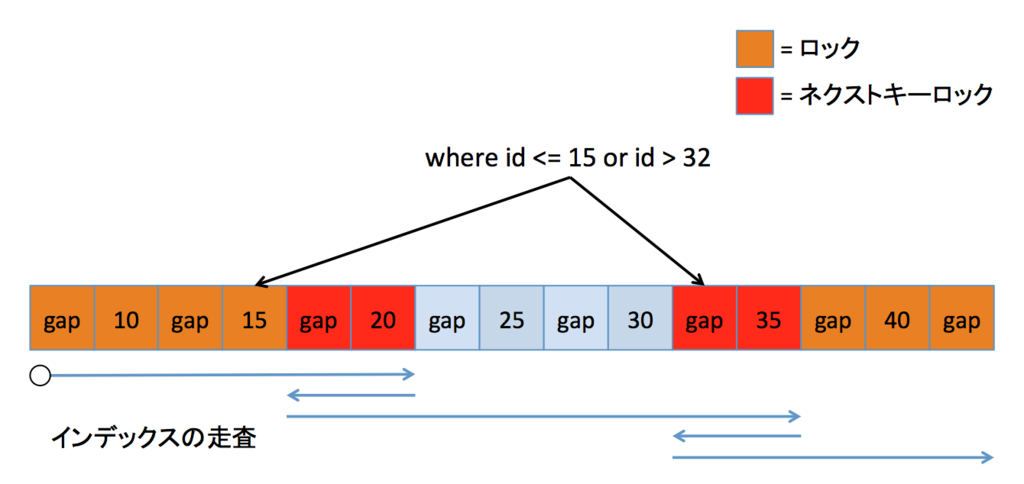
範囲が分割されている場合でも同様に動作します。
おわり
一通り書いてみましたが、間違いがあるかもしれませんのでご注意。ドキュメントやネット上の情報、手元での実験だけでは不明確な部分もあり、ソース嫁という話ではあるのですが、若干のめんどくさみがあるのでもし気が向くことがあれば見てみようと思います。おわり。
Clean Architecture を読んだ感想
Clean Architecture を読んだ感想というかまとめというか、備忘も兼ねて書きたいことをテキトーにメモします。

全体的に、Clean Architecture という設計手法の具体的な How to が書かれているという感じではなく、ソフトウェアを設計する際に大事にするべき考え方の部分を軸に書かれているなあという印象でした。ソフトウェア設計の原則や考え方がざーっと序盤に書かれていて、それらを大事にするとこういうアーキテクチャがいいよね、という流れで Clean Architecture という設計が登場する流れです。ソフトウェア開発って、手法の優劣というか、主張の妥当性を示す決定的な根拠を出すのは難しいと思うのですが、その中でも、アーキテクチャが大事なんだという筆者の主張はそれなりに納得感のある形で伝わってきた気がします。
そんな感じで、優れた設計方法を知るというよりは、優れた設計の背景にある考え方を知るという感覚で読めました。あまりプログラミングや設計に慣れていない自分のような人間にもわかりやすく書かれていて、汎用的な知識として身についたものが結構あったと思います。オブジェクト指向や設計に深い理解がある人にとっては情報量が少ないかもしれないなーという気がしなくもないですが。
設計を題材にした本なので、優れた設計とはこういうものだという話を色々しているのですが、まとめると「変更に強い設計」を優れた設計と考えていいのではないかと思いました。逆に変更に対しての弱さはどこから生まれてくるのかと考えると、おそらく多くの場合で不適切な依存関係からではないかと思います。すなわち、システムやプログラムが疎結合な状態や依存関係がキレイな状態は、変更に強い状態と言えるのではないでしょうか。
で、プログラムをそのような状態にするために、オブジェクト指向プログラミングではポリモーフィズムが活躍するという話が沢山書いてあります。ポリモーフィズムを活用することで詳細な実装を隠し、アダプティブというかプラガブルな設計を作り出すことができるからです。依存関係逆転の原則によれば、ポリモーフィズムを使えば依存関係を自由自在にコントロールできるとも言えます。筆者はこれをオブジェクト指向の最たる強みであるとしています。変更への弱さが不適切な依存関係から生まれるのだとすれば、依存関係をコントロールできれば変更への強さを意図的に作れるからです。
オブジェクト指向についてまだまだ理解が浅い自分にとっては、その辺の考え方も整理された感があります。有名なソフトウェア設計の原則に、この依存関係逆転の原則や、オープンクローズドの原則といったものがありますが、改めてこれらにオブジェクト指向のエッセンスが垣間見えた気がします。「オブジェクト指向プログラミングとは何か」と聞かれたら「抽象でプログラミングする手法」とテキトーに答えていましたが、その点では筆者と考え方自体は近い気がしたので少し安心した感もありました。ちなみにオブジェクト指向以前のパラダイムの言語でも、一応ポリモーフィズム的なことは実現できたらしいのですが、関数ポインタを使うため危険性が高く、実用的ではなかったとのことです。
ただ、抽象化にはコストが伴うということは多くの人が経験的に知っていると思います。過激に抽象化して変更に強い状態を作るのは手間のかかる作業だし、逆に構造を把握しづらくなったりもします(YAGNI なんて言葉が生まれるくらいですから)。設計なんて考えずに、動けばいいやで書いたほうがサクッと作れたりするものです。しかしこの方法では機能変更、追加時に高く付きます。すなわち、将来のために投資するか否かという選択がここにあるわけです。投資すべきかどうかを絶対的に評価/判断する方法があるわけでもなさそうなので、この辺りはアーキテクトの腕の見せどころといったところなのでしょう。適切な意思決定には経験値はもちろん、業務知識なんかも必要になりそうです。とまあそんな感じで、YAGNI や DRY なんかと相反するように見える「優れた設計」についても筆者の意見が書かれていて、なるほどなーという感じでした。
あと個人的に面白いなと思ったのは、デキるアーキテクトは詳細(使うDBとかの具体的な話)の決定をできるだけ遅らせるようにデザインする的な話で、あまりできていなかったことだなーと。決定を遅らせるのが大事というよりは、決定を遅らせても大丈夫なような状態にしておくのが大事ということでしょう。Web サービスを作るときなんかは、開発初期段階でサーバや DB のことをかなり意識してしまっていたので、詳細よりもサービスの本当の価値となるビジネスロジック部分の方にもっとフォーカスしていくべきだと思いました。中核にあるビジネスロジックを捉えることは DDD に限らず大事な気がしますし。Web サービスを作る際に大前提として考えてしまいがちな 「Web で配信する」ということすら意識する必要がないという主張にはハッとした感がありました。
Clean Architecture を導入したプロジェクトはどのようなディレクトリ構成をとるべきなのかとか、ユースケースが実際にはどのように表現されるのかとか、Clean Architecture の具体的な部分はまだ理解していないことだらけなので、テスト的に実践してみようかなーと思います。ただ、こういうシッカリしたアーキテクチャってそれなりの規模のプロジェクトじゃないと有り難さがわからなそうな感はありますが...。
総括として、個人的な本書の位置づけは、ある程度オブジェクト指向を理解できてきたら次のステップとして読みたい本、という感じでした。同列のステップとしてデザインパターンの本などもありだと思いますが、あっちはなんというか具体例の裏にあるエッセンスを自分で掴んでいかないと、汎用的な知識としては得られるものが少ない気がしたので。本書は設計の「考え方」の部分が大きなウェイトを占めていたので、Clean Architecture というアーキテクチャ自体に興味がなくてもなにかしら気づきがありそうな印象を受けました。おわり。
【クラスローダ】JVMが読み込むクラスを見つける仕組み【パッケージ】
NoClassDefFoundError や ClassNotFoundException に遭遇した時など,Java で書くならある程度クラスローディングについて知っておいたほうがいいかなあと思い調べたときのメモ.なんとなくの概要.
クラスローダ
基本的な仕組み
Java アプリケーションは基本的に,複数のファイルに分かれた沢山のクラスによって成り立っています.アプリケーションを動かすためには,これらのクラスを JVM が読み込まなければなりません.Java では JVM のクラスローダと呼ばれる機構がこの処理を担います.クラスローダは,読み込むべきクラスを判断し,ストレージから当該クラスファイルを探し出し,ファイルを開いてクラスをロードします.
クラスロードの戦略は,オンデマンドな感じになっています.アプリケーションの開始時に必要な全てのクラスを読み込むのではなく,実行中に必要になったタイミングで必要になったクラスのロード(検索)をします.
クラスローダは担当検索範囲ごとに複数存在していて,それらが階層構造(親子関係)をとっています.それぞれのクラスローダがやることは同じなのですが,クラスを検索する場所がそれぞれ異なります.あるクラスローダはどこどこのパスからクラスをロードするのを担当して,あるクラスローダは別のパスからロードするのを担当するという感じです.
プログラム実行中に実際にロードを担当する(起点となる)クラスローダは,実行中のクラスをロードしたクラスローダです.ですが,基本的には,親の担当範囲で見つけられるクラスなら親にロードしてもらう,親がロードできなければ子がロードするという風に,上位のクラスローダから順に特定のクラスのロードを試みていきます.この仕組みは委譲(delegate)と呼ばれます.
また,クラスローダは基本的に子にはロードを委譲しません.これは結構重要なポイントです.例えば,クラスローダAの検索範囲にクラスaがあり,その子クラスローダであるクラスローダBの検索範囲にクラスbがあるとします。この場合,クラスaを実行中にクラスのロードの起点になるのはクラスローダAです.すなわち,クラスa実行中には,クラスローダBがロードを担当する範囲にあるクラスbをロード出来ないということを意味します.起点となったクラスローダより階層的に下位に存在するクラスローダは使われないのです。(が,このやり方が問題になるケースも存在するということで,委譲の順番をあえて変更しているサーバ等も一応存在する模様).
このように,ロードに優先順位というか,方向性をもたせることで,複数のクラスローダが同じクラスを重複してロードしたりして競合が発生することを防げます.このような仕組みになっているので,とあるクラスが,起点となるクラスローダの下位クラスローダ配下にしか存在しないクラスに依存する,という設計はよろしくないでしょう.
また,クラスローダは階層構造の横方向にも委譲しません.すなわち,兄弟関係にあるクラスローダ同士はお互いに影響し合わない仕組みになっています.こうすることで,単一のサーバにデプロイされる複数のアプリケーションごとに兄弟関係になるクラスローダを作ることで,それぞれのアプリケーションでバージョンが違うクラスを読み込んだりできます.
基本となるクラスローダ
基本的なクラスローダは,ブートストラップクラスローダ,拡張クラスローダ,システムクラスローダの3つです.これらは挙げた順に親子関係になっています.
ブートストラップクラスローダは JVM そのものの実行に必要になるクラスをロードする基礎的なクラスローダです.JDK のコア API に関するクラスなどがこのクラスローダにロードされます(java.lang.* など.<JAVA_HOME>/lib にあるような jar とかですね).このクラスローダは基本的には JVM 内にネイティブ実装されています.そのおかげで,そもそも最上位のクラスローダは誰がロードするのか問題(パラドックス)を解決できています.
拡張クラスローダは,拡張用ディレクトリ(一般的には <JAVA_HOME>/lib/ext)にあるクラスをロードします.なので,クラスパスを変更することなく基礎的な機能を Java に追加したい場合には,このディレクトリに追加してあげれば簡単に実現できます.
システムクラスローダは,クラスパス(環境変数)で指定している場所のクラスのロードを担当します.普段プログラムを動かすためにクラスパスを追加することがあると思いますが,そのパスのクラスはこいつが読み込んでくれています.また,このシステムクラスローダを親として独自のクラスローダを作成することも可能です(ユーザ定義クラスローダ).ユーザ定義クラスローダを作ることで,アプリケーション単位でクラスローダを割り当て,ライブラリのロード方法を変えたりできます.
ブートストラップクラスローダはネイティブ実装されているのですが,その他のクラスローダは Java オブジェクトとして存在するので,プログラム中でそのインスタンスを取得したりなんてことも簡単にできます.
クラスローディングの流れの大枠
まず,JVM がプログラムを実行中にクラスのロードが必要だと判断すると,クラスローダに処理を依頼します.クラスローダはロードすべきクラスの完全修飾名を基に処理を始めます.完全修飾名とは,com.example.Hoge のようにクラス名とパッケージ名を繋げたものです.クラスローダは自分がどの場所からクラスを探せばよいかは知っていますが,その場所のどのクラスをロードすればよいかは知らないので,この完全修飾名を与えてロードすべきクラスを決定します.
例えば,/usr/local/lib を探すクラスローダがあったとして,JVM がそれに com.example.Hoge クラスをロードしてもらう指示を出した場合,完全修飾名がパスに変換され /usr/local/lib/com/example/Hoge.class をロードしようとします.この際,クラスが見つからない場合には ClassNotFound の例外が投げられることになります.
言い換えると,読み込まれるクラスは,パッケージ名とクラス名,そしてクラスローダの3つによって決定されるということです.なので,完全修飾名が全く同じクラスが別の場所に複数存在していた場合,処理をするクラスローダによって読み込まれるクラスが変わります.また,同名の完全修飾名をもったクラスが複数のクラスローダから検索され得る場合には,一番最初に発見されたクラスがロードされる事になっています.
クラスが無事発見されると,そのクラスが正しい構造になっているかどうかを検証したり,static フィールドを初期化したり,static イニシャライザを実行したりして,クラスを使える状態にします.
おわり
このように Java ではクラスローダという機構がクラスロードを担当しています.他の言語でのクラスロードの仕組みがどうなっているのか少し気になったので,また暇な時に調べて記事にしようかなーと思います.おわり.
参考
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-5.html#jvms-5.3
https://www.ibm.com/developerworks/jp/websphere/library/java/j2ee_classloader/1.html